
GPT-SoVITS | 1分钟微调中文声音克隆教程
这篇文章带你了解如何使用这个最新且强大的声音克隆开源项目:GPT-SoVITS
GPT-SoVITS: https://github.com/RVC-Boss/GPT-SoVITS
Colab: https://colab.research.google.com/github/RVC-Boss/GPT-SoVITS/blob/main/colab_webui.ipynb
前言
今天测试了下一个开源的声音克隆开源项目:GPT-SoVITS,深感强大。特此记录一下。
GPT-SoVITS: https://github.com/RVC-Boss/GPT-SoVITS
Colab: https://colab.research.google.com/github/RVC-Boss/GPT-SoVITS/blob/main/colab_webui.ipynb
使用Colab的视频教程可参考youtube:https://www.youtube.com/watch?v=8JFUl2pFDAA&t=3s
1. 使用Colab
使用google Colab notbook 方式,可以不用占用自己本地资源,它的详细教程可以参考我贴的视频:https://www.youtube.com/watch?v=8JFUl2pFDAA&t=3s
2. 使用windows 本地训练
进入作者的github 仓库: https://github.com/RVC-Boss/GPT-SoVITS/tree/main
在readme中找到下面链接:prezip

把它下载下来,并解压。解压完成后进入目录,双击文件go-webui.bat。如果一切顺利的话会直接跳转到web界面
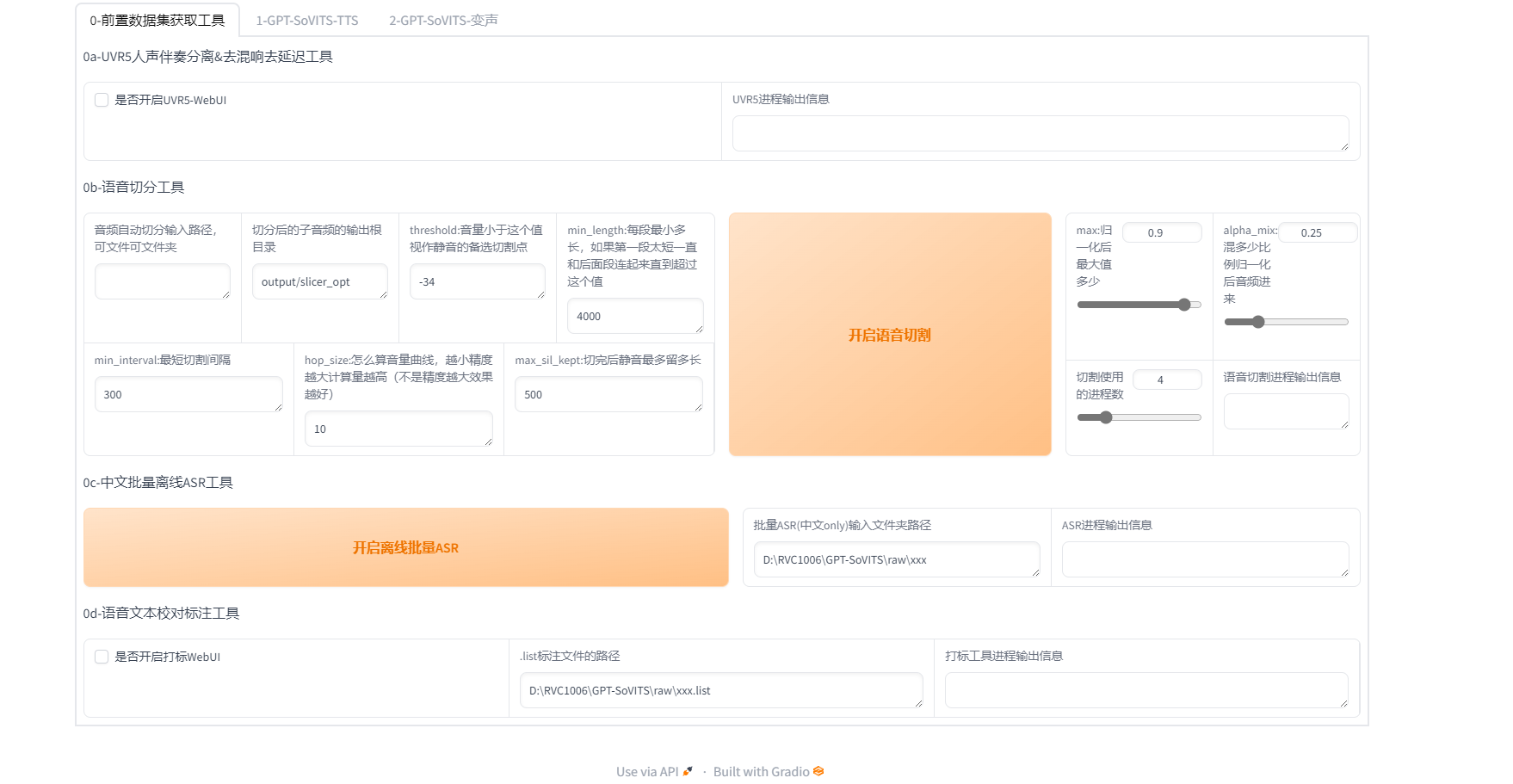
1. 前置数据准备
1. UVR5人声伴奏分离&去混响去延迟工具
准备1分钟左右的人声数据音频文件,最好是纯人声,不要有bgm。如果有bgm的话,则需要进行人声伴奏分离,如下勾选按钮触发
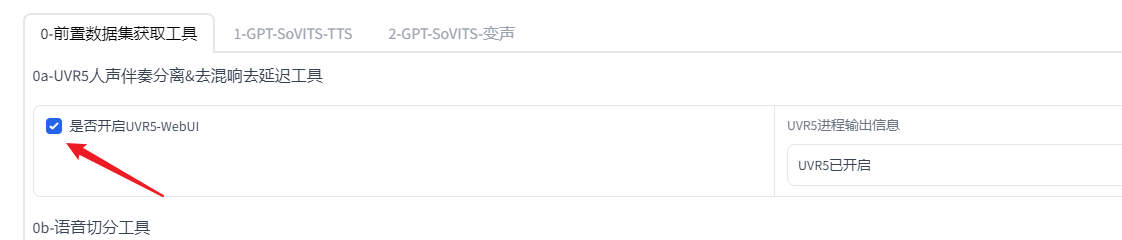
加载成功后可以在终端中看到url。一般会直接跳转,如果没有跳转,则直接复制url到浏览器打开即可。

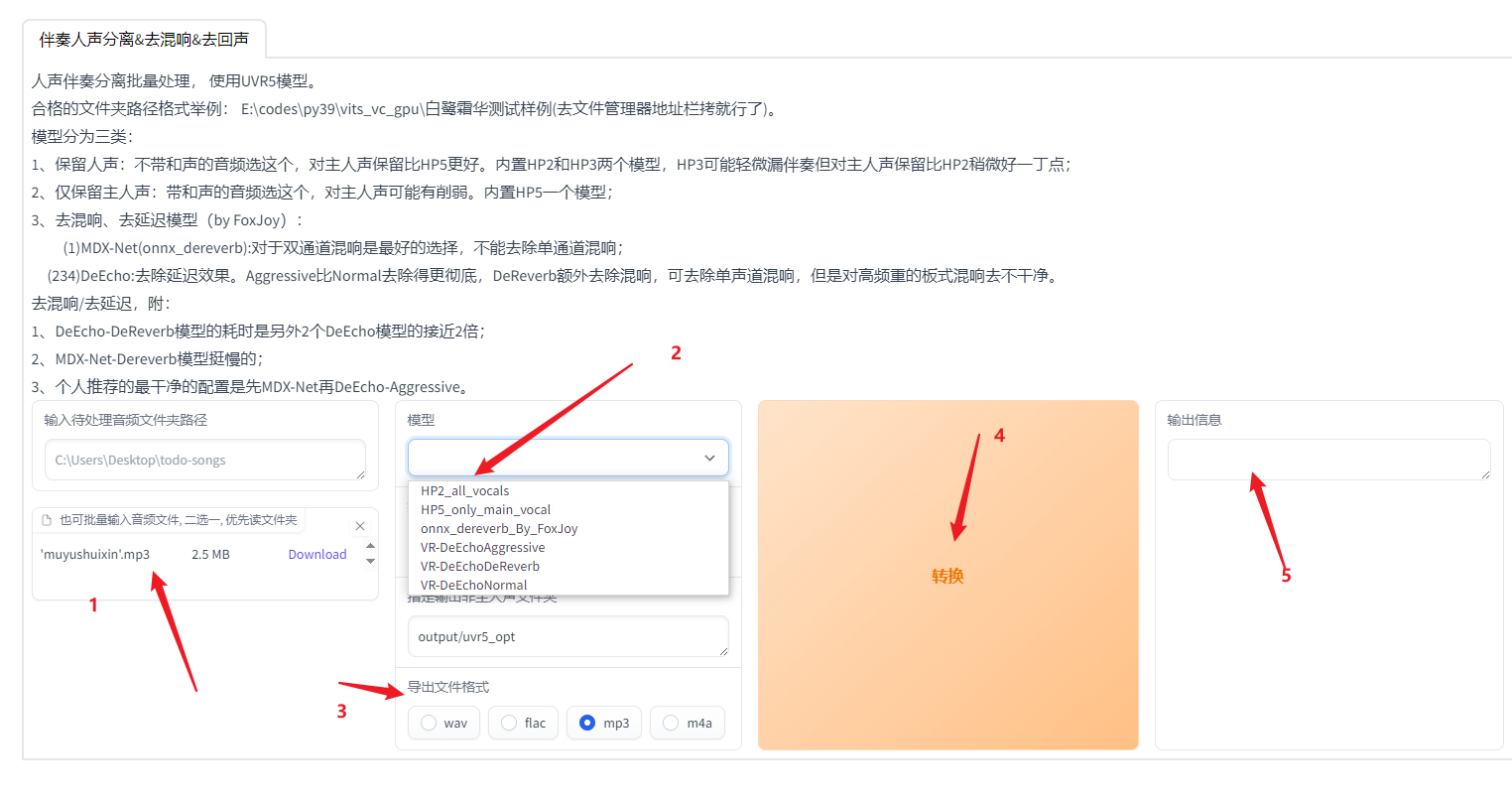
然后打开需要进行分离的音频==》选择模型,模型选择在web界面中有建议,这里我直接使用HP5模型==》接着选择输出格式,一般MP3即可。==》完成后点击转换===》最后转换完成即可在保存路径中看到,默认保存在output/uvr5_opt。
2. 语音切分
注意,把刚才只有人声的音频文件路径复制到下面方框内,其他参数保持默认,点击开启语音切割。
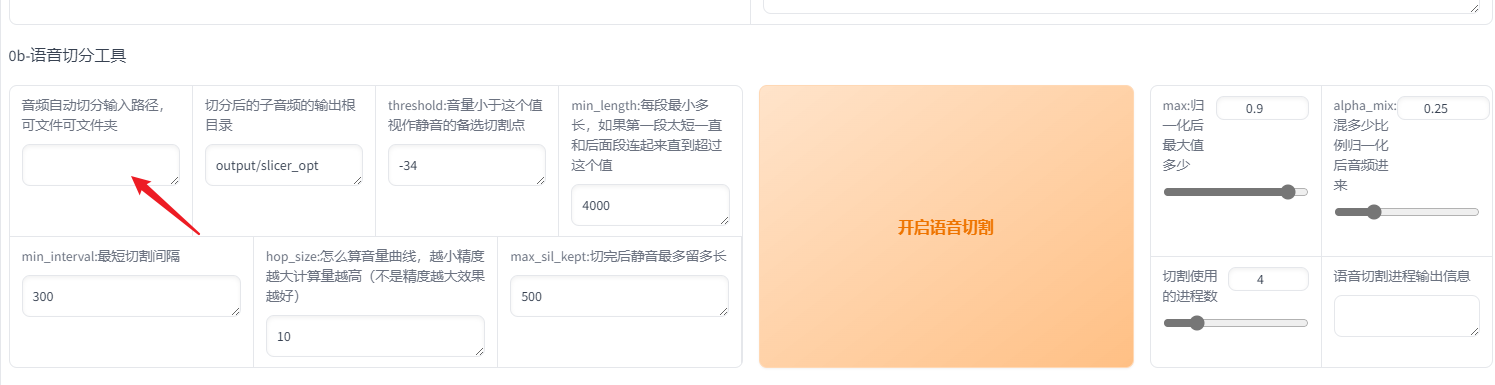
切割结束后可以在目录里的output/slicer_opt 里面找到。
3. 中文批量离线ASR工具
把刚才output/slicer_opt的完整路径复制到下面方框,点击开启离线批量ASR,等待任务完成即可。

任务完成后,可以在GPT-SoVITS-beta\output\asr_opt下面找到
4. 语音文本校对标注工具
对上面处理好的asr list,可以打开语音文本校对标注工具进行校准。输入刚才生成的list文件路径,触发即可。

2. TTS 微调
1. 训练集格式化
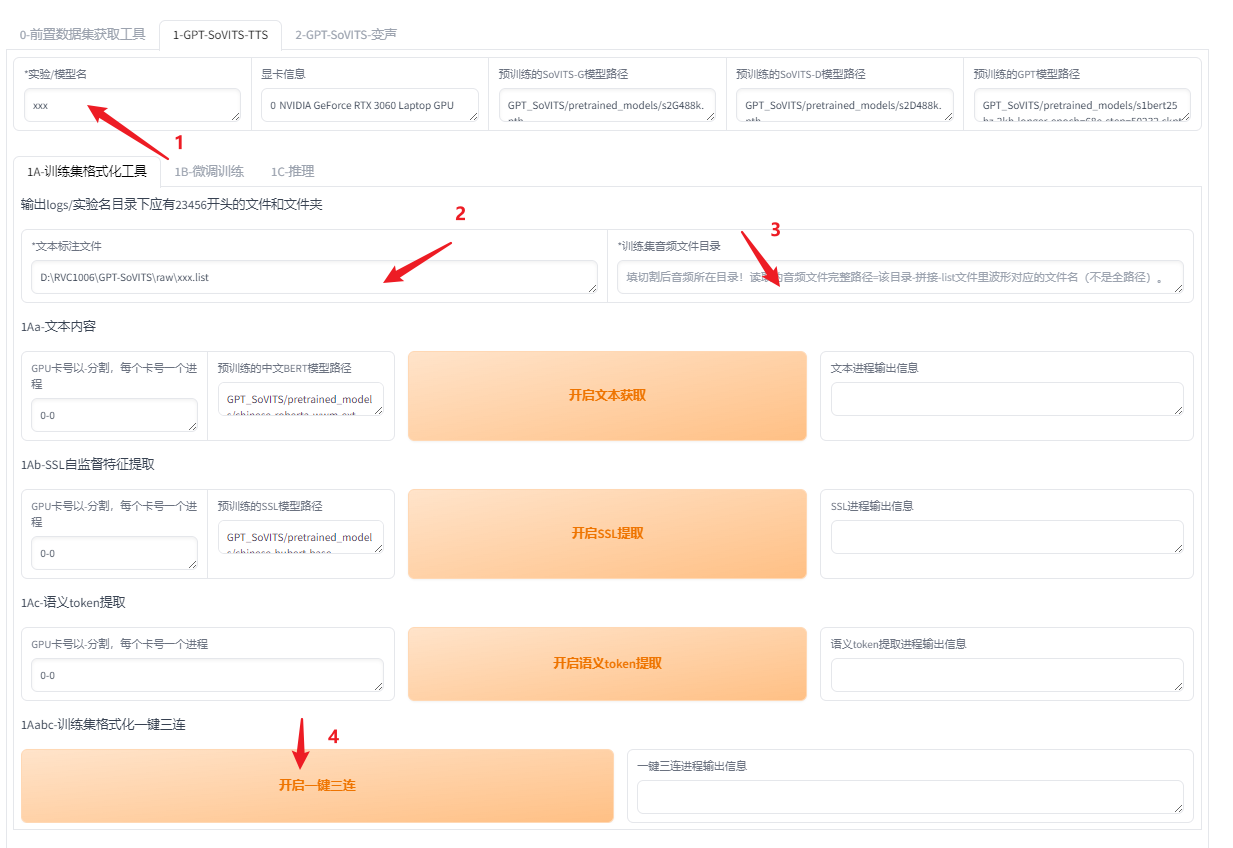
如上图,给微调的模型取个名字(不要中文),将之前处理好的数据list文件路径和切割后的音频目录分别填在2,3中。其他参数保持默认,最后点击开启一键三连. 如果第4步报错,则再点击一次重新运行看看。
2. 微调训练
进入微调训练面板
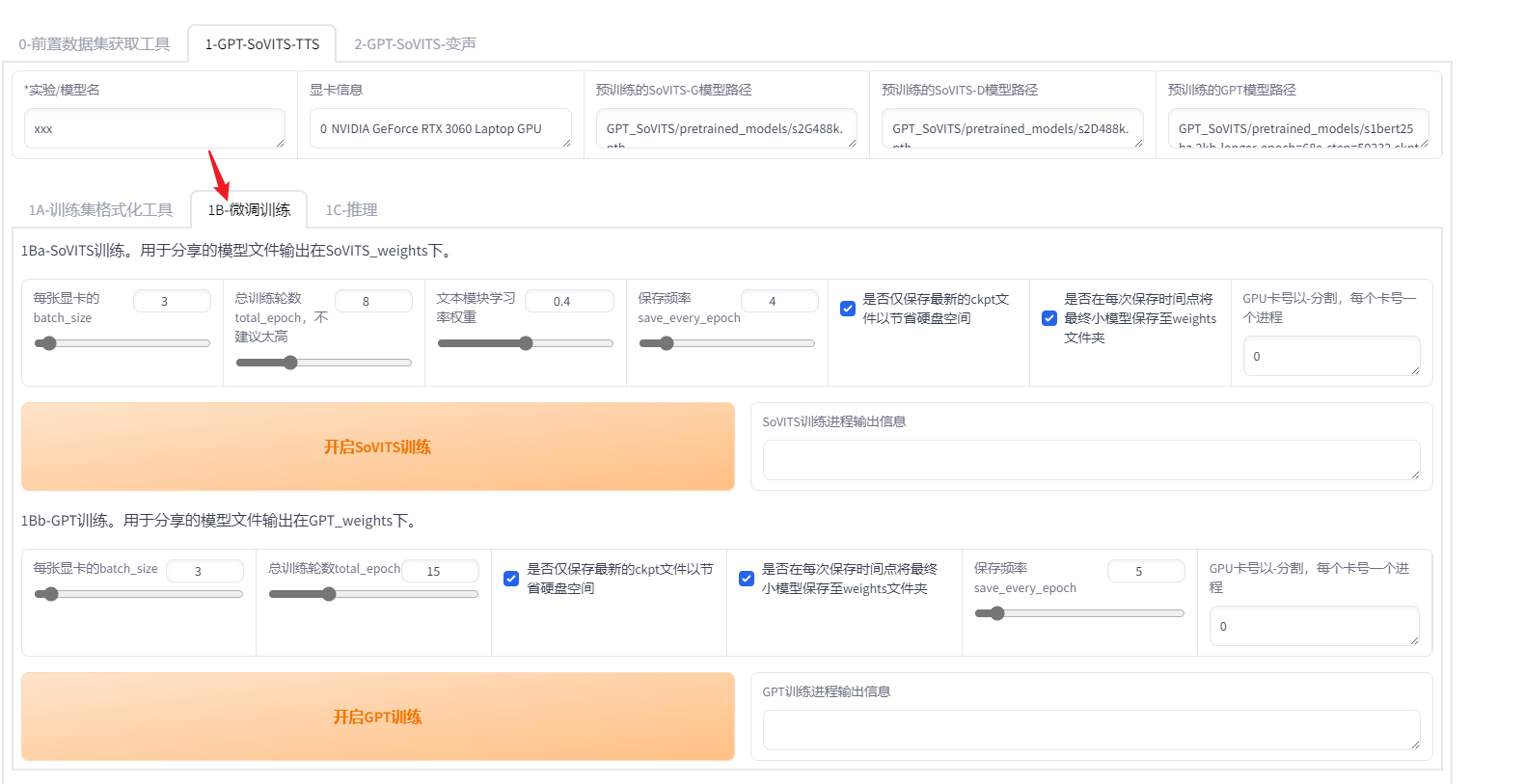
依次点击开启soVITS训练和gpt训练即可。
成功之后可以在SoVITS_weights和\GPT_weights目录里面找到训练好的模型。数字最大的哪个模型就是最终训练的模型,其他的都属于训练过程中保存的。
3. 推理
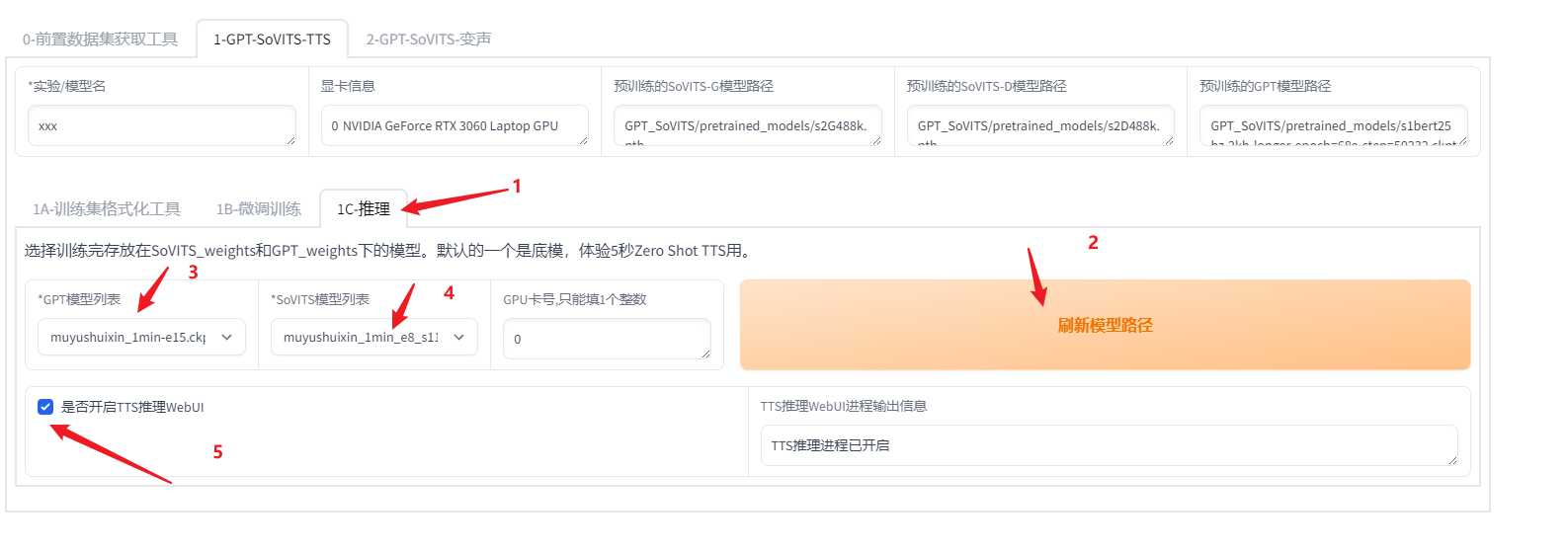
最后一步,就是使用训练好的模型进行推理了。
进入推理面板,首先刷新模型路径,刷新之后,可以找到刚才训练的模型,然后分别选择刚才训练好的gpt和sovits模型文件,点击开启TTS 推理webUI,稍等片刻,便可在终端中找到web ui url的地址。打开后是如下web ui界面
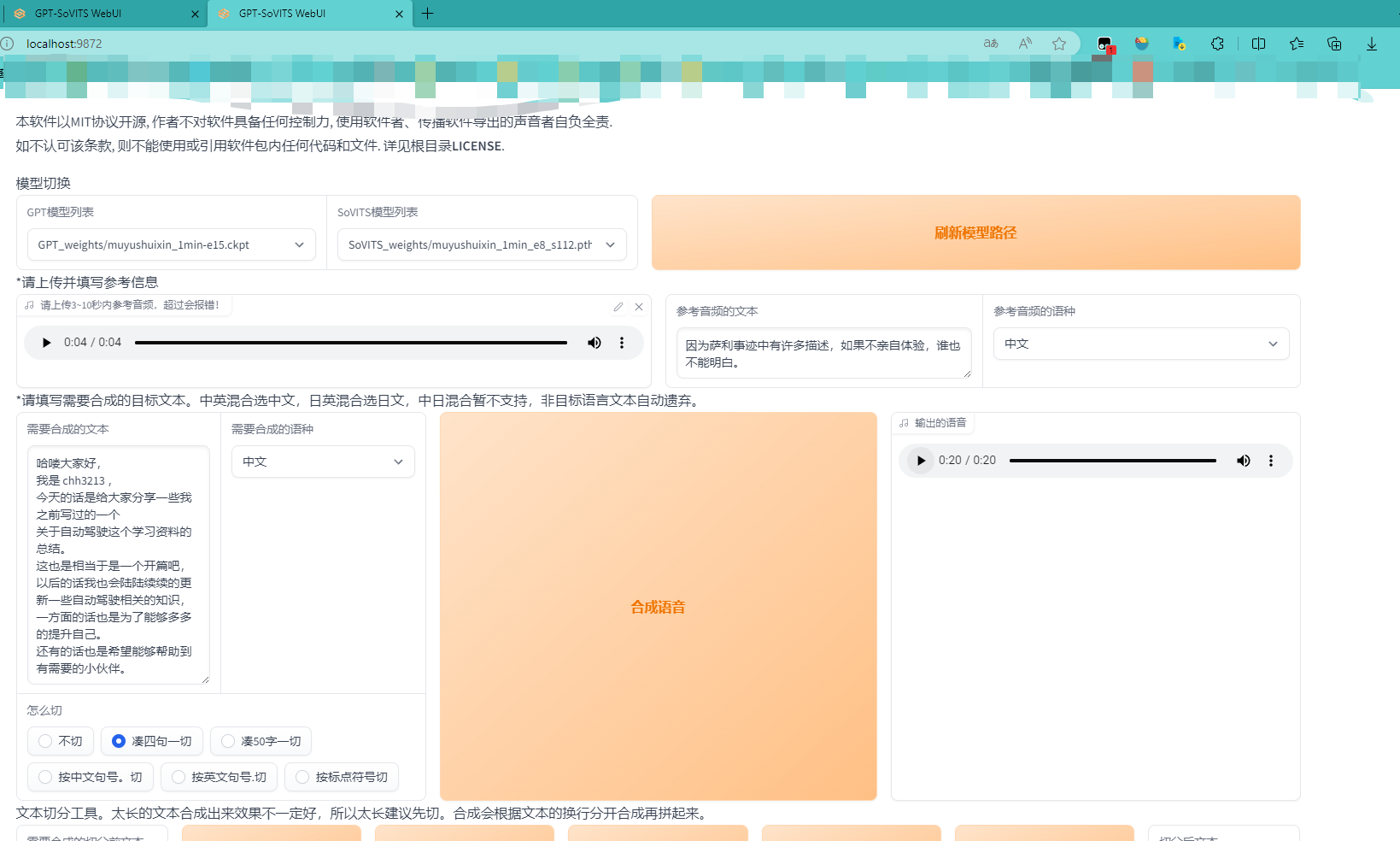
首先需要填入的就是第一步前置数据处理时切分的音频,随便选择一个填入,并将对应的文本填入。这里我处理的音频是中文,所以选择中文。

在下面输入自己想合成的文本,切分方式可以挨个尝试,看看什么方式效果更好。点击合成,稍等片刻后就可以查看合成的效果啦。个人认为合成后的效果还不错嘿嘿。

以上就是详细的使用步骤了。